테스트코드 작성 시 Stub과 Fake를 나누는 기준
잡만리(Jobmanli) 프로젝트를 개발하면서, 유저 도메인의 유스케이스를 Mockito 모듈에 의존성 없이 테스트 작성을 하는 것을 고려해 보았습니다.
이 과정에서 UserService 단위 테스트를 구성하려고 했고, Repository에 대한 부분을 "과연 데이터베이스까지 사용해야 할까?"라는 고민을 하게 되었습니다.
보통 데이터베이스까지 사용한다고 하면 TestContainer나 H2를 활용하여 처리하는 것을 떠올리게 됩니다. 하지만 여기서 드는 의문은 "유저 도메인의 순수 유스케이스를 테스트하는데 굳이 데이터베이스까지 가야 하는가?" 입니다.
물론 데이터베이스까지 확인해야 하는 포인트도 예외적으로 존재합니다. 예를 들어 Infra 계층에서의 장애 핸들링으로 비즈니스 로직이 확장되는 경우에는 이러한 부분을 고려해야 합니다.
그렇기에 최대한 Infra 레이어에서의 에러나 기타 핸들링을 최소화하는 것이 좋고, 불가피하다면 이는 통합 테스트(Integration Test) 를 통해서 증명하는 것이 좋습니다.
아키텍처 관점에서의 고찰
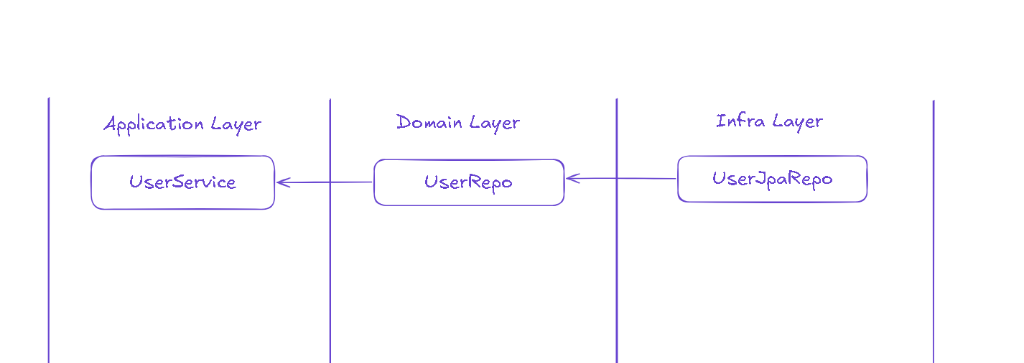
Infra 레벨에서는 저장 공간에 대한 책임을 지고 있으며, 엄밀히 말해 이것은 Application Layer의 로직과 강하게 결합된 형태가 아닙니다.
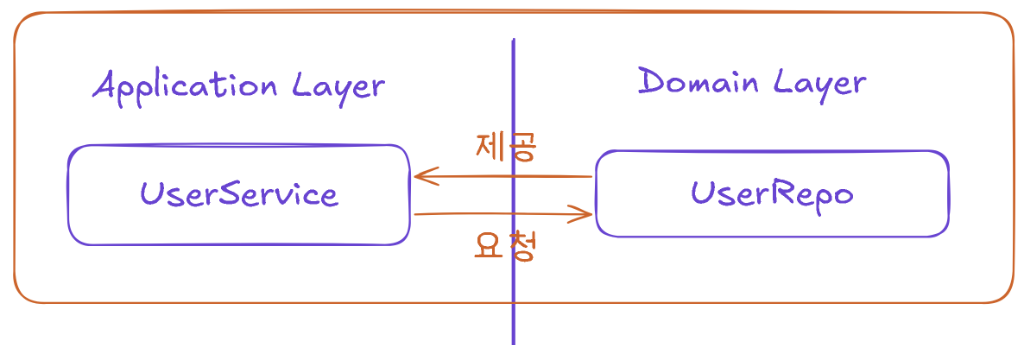
Application Layer에서 Domain Layer의 Repository 인터페이스를 거쳐 데이터를 요청하면, 구현체가 이를 제공하는 형상이기 때문입니다. 즉, UserService가 요구하는 기능을 충분히 제공할 수 있다면 Repository 구현체가 반드시 강력한 상태(Strongly Stateful)를 가질 필요는 없을 수도 있다는 의미입니다.
예를 들어, UserService가 ID 1번에 대한 Profile을 찾는다고 가정해 봅시다.
테스트 더블(Test Double)은 그저 그에 맞는 정보를 반환하기만 하면 됩니다. 만약 UserService의 실패 케이스를 처리하고자 한다면 Optional.empty()를 반환하면 그만입니다.
이러한 형태가 보통 Stub 내에서 단순 Fixture 기반으로 동작하는 흐름입니다. (Stateless한 형태의 Stub)
Stub의 구성과 특징
때에 따라서 Stub 내부 메소드 구간에서 상태를 저장할 수도 있습니다. 그러면 "Fake랑 뭐가 다르냐?" 라고 할 수 있겠지만, 차이점은 책임의 범위입니다.
Stub은 DB 내의 ID 생성 전략이나, 부분적인 DB 레벨에서의 에러 전파에 대한 부분을 따로 구성하지 않습니다. Stub은 State의 수준을 최소화하는 것에 의의를 둡니다.
DB와 비슷한 동작을 하려면 Map 형태로 Fake를 구성하지만, Stub은 보통 데이터가 들어가고 단순히 다시 응답하는 형태로 쓰이기 때문에 주로 List 형태를 사용합니다.
만약 Stub에 Map 형태가 들어오게 되면, ID에 대한 전략이 Stub과 결합되어야 하는 경우가 생기기 때문에 이러한 부분을 최소화해야 합니다.
Stub 객체의 구성 원칙
보통 Stub은 특정 정보를 최소한의 State로 관리하며, 이를 제공해주도록 구성합니다. 또한 메소드 수준의 테스트에서 격리성을 함께 지켜주어야 합니다. 데이터의 PK 생성과 같은 로직 상의 책임은 가지지 않는 것이 좋습니다.
저는 아래와 같은 원칙을 토대로 Stub을 구성합니다.
- Stub Repo를 거치더라도 ID가 Null일 수 있다.
- 생성 전략과 같은 부분은 ID 값이 없더라도 유스케이스 내에서의 아이디 중복 체크와 같은 로직을 충분히 확인할 수 있습니다.
- 즉, 억지로 ID 주입을 할 필요성은 없다는 것입니다.
visibleForTesting패턴 활용- 도메인 코드 내에
testInstance()팩토리 메소드 등을 제공하여 사용합니다. - 실제 운영 코드에 테스트용 코드가 섞이는 것을 꺼리는 시각도 있지만, 실제로는 의미상 충분히 구분할 수 있다면 이러한 형태가
Reflect와 같은 코드 복잡도를 줄이는 데 도움을 줍니다.
- 도메인 코드 내에
- 데이터 저장소로
List사용- 데이터가 여러 개일 수 있으므로
List를 통해 저장합니다.
- 데이터가 여러 개일 수 있으므로
Map대신List를 사용하는 이유- Stub 자체가 ID 생성에 대한 책임을 질 필요가 없기 때문입니다.
Stub 선택 시의 단점
물론 Stub을 선택했을 때 잃는 부분들도 명확합니다:
- Unique Constraint (유니크 제약조건) 검증 불가능
- 실제 DB 에러 코드 재현 불가능
- Repository 계약(Contract) 검증 불가
- Stub 기반 테스트가 통과해도 실제 DB 환경에서는 실패할 가능성 존재
이러한 부분은 Infra에서 파생된 에러나 검증에 대한 확장이 힘들다는 것을 의미합니다. 하지만 이러한 검증을 위해 불가피하게 복잡성을 추가해야 한다면, 오히려
Stub을 쓰는 것이 독이 될 수도 있음을 인지해야 합니다.
Fake 객체로 구성한다면?
반면 Fake는 보통 실제 구현과 동일한 인터페이스/행위를 모방하지만 실제 DB는 아닌 객체를 의미합니다.
이는 해당 원본 객체의 현실 동작을 위한 모방된 기능까지 만들어야 하기 때문에, ID 생성 전략이나 트랜잭션 구간에 대한 책임을 가져야 합니다.
이는 엄밀히 말하면 유닛 테스트보다 는 통합 테스트에 가깝습니다. 하지만 실제 MySQL이 아닌 좀 더 가벼운 메모리 기반으로 하는 통합 테스트는, 실제 동작과 미세하게 다를 수 있기에 "통합 테스트치곤 애매한 작업"이 될 수도 있습니다.
결론
Unit 형태의 격리성 중심의 테스트를 진행해야 한다면, Fake보다는 Stub 형태의 선택이 옳다고 생각합니다.
사이드 이펙트가 생길 수 있는 포인트를 줄여서, 오직 서비스 레이어의 유스케이스 로직에만 집중할 수 있도록 테스트를 짜는 것에 의의를 두는 것이 더 낫다는 의미입니다.
save시 ID 생성에 대한 책임 검증이 필요하다면, 이는 서비스 레이어가 아닌 Repository에 대한 테스트를 별도로 진행하는 것이 옳습니다.