도메인 및 엔드 포인트를 나누는 기준
잡만리(Jobmanli) 프로젝트의 기획 단계에서 클라이언트 화면 설계를 하던 중 고민이 생겼습니다.
단일 페이지 내에 필요한 여러 요소들을 한 번의 API 호출로 모두 가져오는 것과, 성격에 따라 나누어 2번 이상의 I/O로 호출하는 것 사이에서 선택을 해야 했습니다. 이 포인트(어디서 나눌 것인가)를 어떻게 잡느냐에 따라 전체적인 설계 방식과 최적화 전략이 달라지기 때문에 신중하게 접근하고자 했습니다.
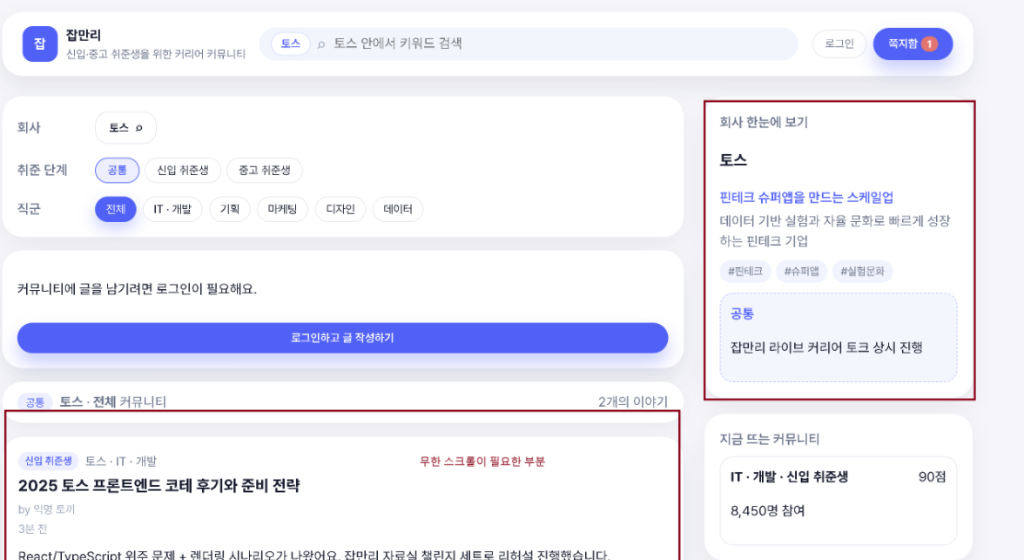
두 가지 성격의 데이터 공존
이 페이지에는 토스라는 회사의 정보 와 토스 회사 내 직군별 게시판(커뮤니티) 이 함께 노출됩니다.
사용자 입장에서는 한 화면에서 동시에 보여지므로, 개발 초기에는 한 번의 Network I/O로 모든 데이터를 묶어서 응답하는 방식(Aggregated API) 이 가장 직관적이고 효율적으로 보일 수 있습니다.
데이터 변경 주기와 캐싱 전략의 충돌
하지만 각 데이터의 속성을 자세히 뜯어보면, 서로 다른 생명주기(Lifecycle)를 가지고 있음을 알 수 있습니다.
1. 정적 데이터 - 회사 및 직군 정보
회사 이름, 로고, 직군 목록과 같은 정보는 변경 빈도가 매우 낮습니다. 관리자가 정보를 수정하지 않는 한 변하지 않는 정적 데이터(Static Data)에 가깝습니다.
따라서 이 영역은 주문형 ISR(Incremental Static Regeneration)과 같은 전략을 사용하여 서버 부하를 최소화할 수 있습니다. 클라이언트나 CDN 입장에서 장기간 캐싱해도 부작용이 거의 없는 안전한 데이터입니다.
2. 동적 데이터 - 실시간 피드
반면 피드 영역은 성격이 완전히 다릅니다. 게시글은 사용자에 의해 실시간으로 작성, 수정, 삭제됩니다.
또한 무한 스크롤 구조에서는 사용자가 새로고침할 때마다 상단 피드의 내용이 달라질 가능성이 높습니다. 이러한 변동성 큰 데이터(Volatile Data) 를 클라이언트 측에서 과도하게 캐싱하면, 사용자는 이미 삭제된 글을 보거나 최신 글을 놓치는 등 나쁜 경험을 하게 됩니다.
해결 - 성격에 따른 분리
결국 두 영역은 변경 주기(Frequency of Change) 와 캐싱 전략(Caching Strategy) 이 정반대이므로, API 또한 명확히 분리하는 것이 옳다고 판단했습니다.
- Company Info API - 높은 캐시 TTL(Time-To-Live) 적용, ISR 활용 가능
- Community Feed API - 짧은 캐시 혹은 No-Cache, 실시간성 보장
결론
API 엔드포인트 설계 시, 단순히 "화면(UI)에 같이 보이니까 하나로 묶는다"는 View 중심의 접근보다는, 데이터의 본질적인 성격(변경 빈도, 실시간성, 라이프사이클) 에 집중해야 함을 느꼈습니다.
클라이언트가 데이터를 언제 갱신해야 하는가, 어떤 시점에 사용하는가를 기준으로 엔드포인트를 구성해야, 추후 비즈니스 로직이 복잡해지더라도 유연한 유지보수와 정교한 성능 최적화가 가능해집니다.