MySQL connection pool 크기를 정하는 기준
다양한 프로젝트를 진행하면서, 한때는 Connection Pool 크기가 크면 클수록 더 많은 요청을 처리할 수 있을 것이라고 막연하게 생각했던 적이 있었습니다. 하지만 실제로는 이 크기를 무작정 늘렸을 때 오히려 TPS(Transaction Per Second)가 낮아지고, 시스템 전반의 성능이 저하되는 현상을 목격했습니다.
왜 자원을 더 많이 할당했는데 성능은 거꾸로 떨어졌을까요? 그 이유와 적정 크기를 정하는 기준에 대해 정리해 보았습니다.
Connection Pool 크기가 시스템에 미치는 영향
위 그림과 같은 구조를 생각해보면, Backend Server는 Connection Pool을 통해 MySQL에 연결됩니다. 만약 MySQL의 최대 접속 가능 수(max_connections)가 100이라면, 서버의 풀 크기도 100으로 맞추는 것이 가장 효율적이라고 생각하기 쉽습니다.
하지만 실제로는 자원의 경합이라는 문제가 발생합니다.
💡 자원의 경합(Resource Contention)이란?
한정된 공유 자원(CPU, 메모리, 디스크 I/O 등)을 여러 프로세스나 쓰레드가 동시에 사용하려고 다투는 상태를 말합니다. 이 과정에서 대기 시간이 생기거나 관리를 위한 추가적인 비용(오버헤드)이 발생하여 시스템 성능에 영향을 주게 됩니다.
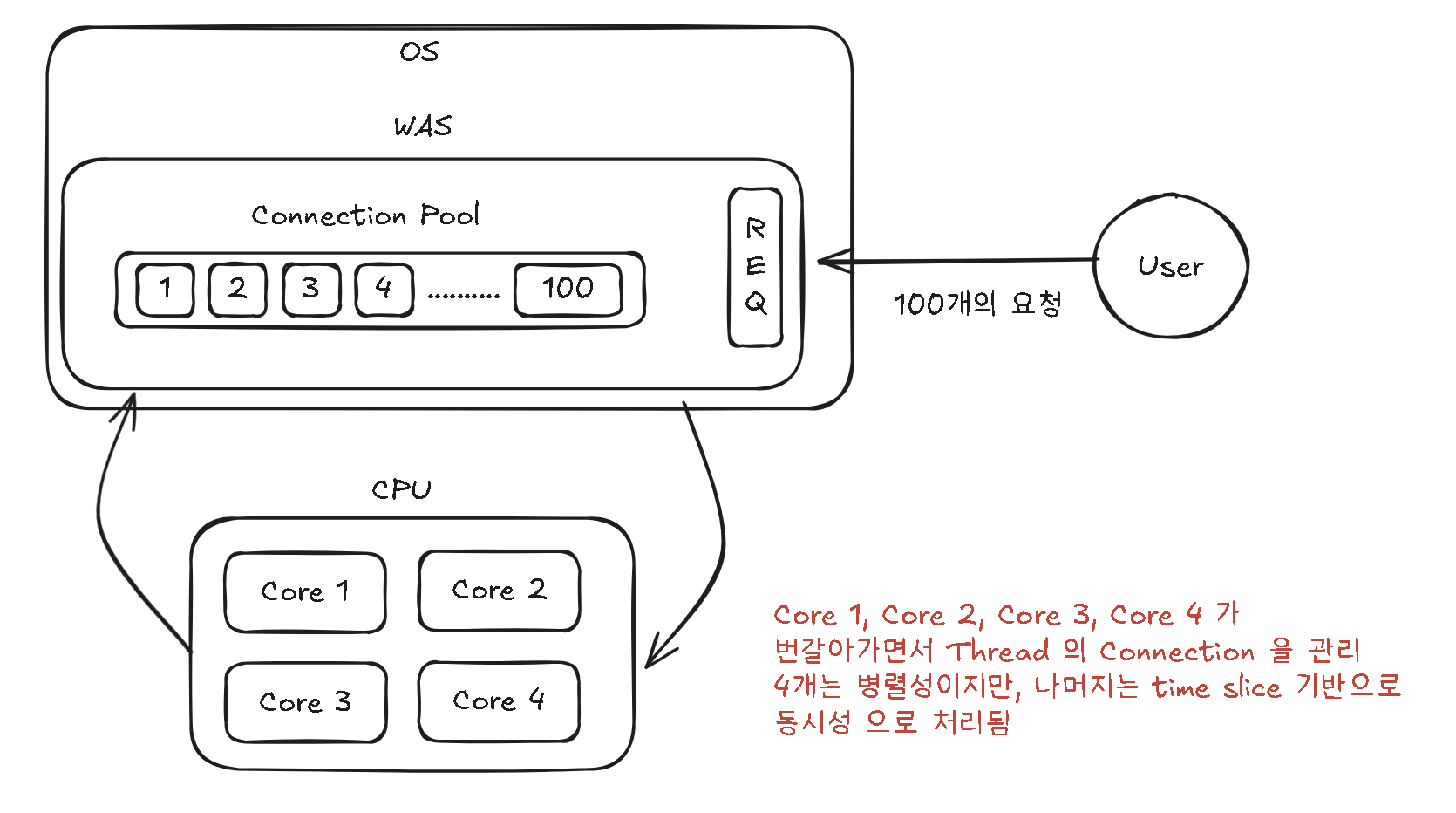
Spring Boot와 같은 전통적인 Blocking I/O 모델에서는 보통 request-per-thread 구조를 사용합니다. 즉, 100개의 Connection Pool을 활성화하면 이를 처리하기 위해 100개의 쓰레드가 생성됩니다.
문제는 운영체제(OS)의 하드웨어가 이 100개의 쓰레드를 실제로 '동시에' 처리할 수 없다는 점입니다. 예를 들어 서버의 코어가 4개라면, CPU는 이 100개의 쓰레드를 아주 짧은 시간 동안 번갈아가며 실행해야 합니다.
컨텍스트 스위칭(Context Switching)의 함정
💡 컨텍스트 스위칭이란?
CPU가 현재 실행 중인 쓰레드의 상태를 저장하고, 다음 순서의 쓰레드 상태를 불러오는 과정을 말합니다.
이 과정은 매우 빈번하게 일어나며, 그 자체로 CPU 자원을 소모하는 비싼 작업입니다. 쓰레드가 너무 많아지면 CPU는 실제 로직을 계산하는 시간보다 이 쓰레드들을 관리하고 교체하는 데 더 많은 시간을 쓰게 됩니다. 결과적으로 전체적인 시스템 성능이 무너지게 되는 것이죠.
그럼 어떻게 잡아야 할까?
Spring 진영에서 널리 쓰이는 HikariCP 라이브러리의 개발팀은 벤치마크를 통해 아래와 같은 권장 공식을 제안합니다.
connections = ((core_count * 2) + effective_spindle_count)
- core_count: CPU의 코어 수
- effective_spindle_count: DB 서버의 물리적인 하드디스크(Spindle) 개수
예를 들어, 4코어 1디스크 서버라면 (4 * 2) + 1 = 9 정도가 적정 수준이라는 의미입니다. 예상보다 훨씬 적은 수치에 놀라시는 분들도 많을 것입니다.
실제 적용 시 고려할 점
공식으로 나온 값이라 하더라도 절대적인 것은 아닙니다. 아래 단계에 따라 최적의 값을 찾아가는 과정이 필요합니다.
- 기본 공식으로 기준점 산출: 수식을 통해 대략적인 출발점을 잡습니다.
- DB 가용 자원 확인: DB 서버 자체가 감당할 수 있는 전체 Connection 수를 넘지 않도록 합니다.
- 점진적 튜닝: 기본값(보통 10)부터 시작해 부하 테스트를 진행하며 조금씩 늘려봅니다.
- 모니터링: TPS가 꺾이는 지점(임계점)을 확인하고, 병목이 CPU인지 I/O인지 파악하여 최종 수치를 확정합니다.
이와 같은 부하 테스트 과정을 거쳐야만, 스트레스 구간에서도 시스템이 뻗지 않고 안정적으로 버틸 수 있는 적정 수치를 찾을 수 있습니다.
Connection Pool의 본질적인 특성
우리가 왜 번거롭게 Connection Pool을 사용하는지 다시 생각해 볼 필요가 있습니다. 데이터베이스와 연결을 맺는 과정(Handshake)은 상당히 무거운 작업입니다.
- 미리 생성: 자원을 미리 할당해놓고 재사용함으로써 생성 비용을 절감합니다.
- 상한선 제어: 무분별한 연결 생성을 막아 DB 서버가 과부하로 죽는 것을 방지하는 '방어막' 역할을 합니다.
결국 Connection Pool 튜닝의 핵심은 CPU 코어가 감당할 수 있는 수준 내에서 쓰레드 경합을 최소화하고, I/O 대기 시간을 효율적으로 활용하는 균형점을 찾는 것입니다.
결론
"많을수록 성능이 좋다"는 생각은 적어도 Connection Pool 설정에서는 위험한 오산입니다. 오히려 작은 풀 크기가 더 높은 처리량과 낮은 응답 시간을 보장하는 경우가 많습니다.
오늘도 시스템의 코어 수와 디스크 환경을 먼저 살피고, 직접 부하를 걸어보며 여러분의 서비스에 맞는 'Golden Number'를 찾아보시길 바랍니다.